Orchestrating Agentic and Multimodal AI Pipelines with Apache Camel and LangChain4j: A Paradigm Shift for Enterprise Reliability

The accelerating adoption of artificial intelligence in enterprise environments has propelled systems beyond simplistic model calls into complex, multi-step workflows that meticulously combine reasoning, retrieval, and action. This evolution introduces agentic AI, where a model functions as a sophisticated reasoning agent, autonomously deciding on tool utilization, information retrieval, and task sequencing. Concurrently, multimodal AI integrates the capability to process diverse input types—such as text, images, and structured data—within a unified pipeline. While both patterns offer immense potential for innovation and efficiency, their implementation in production settings significantly escalates engineering complexity, often leading to substantial operational challenges.
The Growing Pains of Enterprise AI: A Production Crisis
Despite the advanced capabilities of modern AI models, a significant proportion of enterprise AI initiatives falter not due to inherent model weaknesses but because of inadequately designed surrounding systems. As organizations increasingly integrate large language models (LLMs), vector databases, and vision models, recurring production issues plague their efforts: fragile pipelines prone to breakdowns, opaque failure mechanisms, exorbitant operational costs, and insufficient control over AI workflows. These challenges are not merely anecdotal but are consistently highlighted by industry benchmarks and reports.

A seminal 2026 Fivetran benchmark survey, encompassing five hundred enterprise leaders, revealed a startling statistic: ninety-seven percent reported that pipeline failures significantly impeded their AI programs. More critically, fifty-three percent of engineering capacity was reportedly consumed solely by pipeline maintenance, diverting critical resources from innovation to upkeep. Echoing these concerns, MIT’s 2025 NANDA report indicated that a staggering ninety-five percent of generative AI pilots failed to achieve measurable business impact, attributing the core issue not to model quality but to flawed enterprise integration. Further underscoring this pervasive struggle, an S&P Global Market Intelligence survey found that forty-two percent of companies abandoned most of their AI initiatives in 2025, a substantial increase from seventeen percent in 2024. On average, organizations scrapped forty-six percent of proofs of concept before they ever reached production. These statistics collectively paint a clear picture: the fundamental problem lies not in the intelligence of the models themselves, but in the overarching management and orchestration of these intricate AI components within existing enterprise infrastructure.
The Paradigm Shift: From Model-Centric to System-Centric AI
Traditional AI tutorials often simplify the process to a direct model call. However, real-world production systems demand a more holistic approach that encompasses efficient management and containment of the model within a broader ecosystem. In enterprise AI workflows, this translates into strategic decisions regarding when and how to invoke an LLM, selecting appropriate tools for its access, integrating non-LLM models for reliable, rule-based tasks, ensuring graceful handling of partial failures, and generating structured outputs suitable for audit and compliance. It is precisely at this juncture that robust AI pipeline orchestration, particularly with an embedding agent, becomes indispensable. An agent, in this context, transcends a simple LLM operating in a loop; it functions as a reasoning component seamlessly integrated into a larger, meticulously managed execution system. This setup re-emphasizes the enduring value of proven integration methods derived from traditional systems, ensuring the AI infrastructure remains resilient, efficient, and governable.
Orchestration as the Key: Why Apache Camel Fits Agent-Based AI Workloads
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/207figure-1-1776763977934.jpg)
In many conventional agentic AI implementations, the LLM assumes a dual role as both the reasoning engine and the execution controller. Frameworks like LangChain, CrewAI, and AutoGen empower the agent to determine which tools to invoke, manage conversational memory, and sequence actions, all contained within the agent runtime itself. While these frameworks offer basic retry mechanisms at the API call level, they typically lack native, enterprise-grade resilience patterns such as circuit breakers, comprehensive payload validation, or deterministic fallback routing. This design proves adequate for prototypes and single-user applications but introduces significant challenges in production environments. Error handling necessitates custom code interwoven into the agent’s core logic, complicating failure tracing and debugging. Crucially, there is no clear demarcation between the agent’s decision-making process and the execution of those decisions. While external tools like LangSmith enhance observability, they are not intrinsically embedded within the execution model. Consequently, scaling, versioning, and governance become arduous tasks as the critical control logic resides deeply within the AI layer itself.
An integration framework-based approach fundamentally alters this dynamic by abstracting execution control from the agent and delegating it to a proven orchestration layer. In this revised model, the LLM agent retains its primary function of reasoning and strategic decision-making, but a framework like Apache Camel assumes responsibility for how and when those decisions are executed. Routing, retry mechanisms, circuit breakers, payload validation, and action sequencing are managed by Camel routes, not by the agent. This architectural shift grants engineering teams the same granular operational control over AI workflows that they already exercise over traditional enterprise integrations. This clear separation of concerns enhances maintainability, predictability, and auditability.
Apache Camel, often perceived solely as an integration framework, assumes a more strategic role as an AI control plane in systems heavily reliant on AI. It offers a suite of critical features, including unambiguous routing choices, dynamic context enrichment, robust failure isolation through circuit breakers and retries, and deterministic sequencing for steps that might otherwise be unpredictable. Camel’s design inherently separates reasoning from execution tasks. Rather than embedding control logic within opaque prompts or SDK callbacks, Camel externalizes the control flow into modular routes that are inherently easier to test, monitor, and update. In this synergistic setup, the LLM performs the reasoning, but Camel ultimately dictates the execution.
Acknowledging Tradeoffs and Real-World Constraints
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/1figure-1b-1776763977934.jpg)
While the advantages of using Apache Camel for agent-based AI workloads are substantial, it is important to acknowledge the inherent tradeoffs. As a Java-based framework, Camel presents a steeper adoption curve for teams predominantly working in Python, which remains the dominant language within the AI and machine learning ecosystem. This also implies a narrower selection of AI libraries compared to the expansive Python AI tooling landscape. Furthermore, while Camel routes excel at structured, deterministic workflows, they are less inherently suited for highly dynamic agent actions where the execution path is not known a priori and must emerge from multi-turn LLM reasoning. Debugging complex Camel routes that encapsulate AI interactions can also be more involved than debugging a simple Python script directly invoking an LLM. Finally, the learning curve associated with enterprise integration patterns such as content-based routing, dead-letter channels, and wire taps may be unfamiliar to teams originating from an AI or data science background rather than an enterprise integration background. These limitations do not diminish Camel’s value as a robust orchestration layer but suggest its optimal fit within organizations already invested in Java-based infrastructure and prioritizing production-grade reliability over rapid prototyping speed.
Case Study: The Support Ticket Triage System – A Practical Application
To illustrate these principles, consider a production-grade customer support ticket triage system designed for real-world deployment. This system processes incoming tickets, which comprise a title, a detailed description, optional screenshots, and associated metadata (e.g., submitter details, ticket ID). The system’s objective is to deliver a structured JSON decision that includes:
- Ticket Category: Ranging from bugs and incidents to access requests and feature enhancements.
- Priority Level: Scaled from P0 (critical) to P3 (low).
- Recommended Team: The appropriate internal department for handling.
- Suggested Actions: Ensuing steps to facilitate resolution.
- Citations: References drawn from internal documentation.
- Optional Signals: Insights derived from image analysis (if screenshots are provided).
Crucially, this system operates as a streamlined, non-conversational, and headless process. Its outputs are designed to be deterministic, machine-consumable, and fully auditable, ensuring accountability and oversight rather than engaging in interactive dialogue.
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/155figure-2-1776763977934.jpg)
Architectural Blueprint: An Agent Within a Deterministic Pipeline
The support ticket triage system effectively handles a diverse mix of structured and unstructured inputs: textual descriptions, metadata fields, and optional screenshot attachments, each necessitating distinct processing strategies. Accurately classifying a ticket and assigning a priority requires sophisticated reasoning across all these inputs, moving beyond mere keyword matching. Textual content must be matched against internal documentation using retrieval-augmented generation (RAG) to surface pertinent context and citations. Screenshots, when present, demand separate analysis via a vision model to extract actionable signals, such as error dialogs or UI failures, which then inform the overall triage decision. A purely rule-based system would prove inadequate for this range of inputs, while simply feeding everything into a single LLM without structured control would lead to unpredictable costs and unreliable outputs. The multimodal agentic approach is particularly well-suited here because the system requires an agent capable of reasoning about which capabilities to invoke for each ticket, combined with dedicated models for specialized tasks like image classification, all managed within a deterministic pipeline that guarantees auditable decisions and robust failure handling.
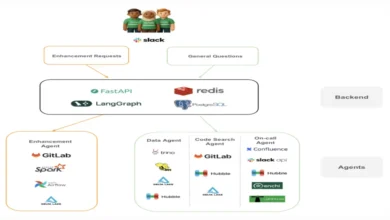
The high-level control flow of this agent-driven multimodal AI pipeline demonstrates how Apache Camel orchestrates LLM reasoning, retrieval-augmented generation, and model serving within a deterministic execution flow. The architecture comprises several key components:
- Apache Camel Routes: Serving as the primary orchestration layer.
- LangChain4j Agent: Responsible for reasoning and tool selection.
- Vector Database (e.g., Qdrant): Supporting retrieval-augmented generation.
- TensorFlow Serving: Hosting a ResNet50 model for image processing.
- External LLM Provider: Compatible with OpenAI standards.
Instead of allowing the agent direct interaction with the underlying infrastructure, it invokes specialized tools. Each tool operates as a Camel-managed operation, with Camel leveraging enterprise integration patterns (EIPs) to enhance the reliability of AI interactions. This design adheres to a fundamental principle: LLMs handle reasoning, dedicated models perform specific serving tasks, and Apache Camel governs the entire process, acting as the ultimate arbiter of execution.
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/131figure-3-1776840498702.jpg)
AI Agents: Orchestrated Tools, Not Autonomous Entities
Within this system, the LangChain4j agent’s access is deliberately restricted to a small, clearly defined set of tools. This limitation ensures that the agent focuses on planning and decision-making rather than direct execution. It determines which tools to use and in what order, while Camel subsequently executes these choices, handling critical operational concerns such as timeouts, retries, and payload validation. This structured setup effectively mitigates a common pitfall in agent systems: the dreaded "endless tool-use loop," where agents can get stuck in unproductive cycles. By clearly delineating roles, the system gains predictability and control.
RAG Reimagined: An Integration Challenge
While retrieval-augmented generation (RAG) is frequently lauded as a transformative AI technique, in practical enterprise applications, it often presents itself more as a critical integration challenge. In this system, documents are ingested into Qdrant during startup, with embeddings generated only once for efficiency. Queries retrieve the Top-K most relevant context chunks, and this retrieved content is seamlessly attached to the exchange through a structured enrichment process. The LLM never directly interacts with the vector database; instead, Camel assumes full responsibility for the retrieval process, enforcing limits on payload size and deliberately incorporating citations. This ensures that context injection remains fully observable, constrained, and auditable. Consequently, RAG transforms into a predictable and reliable mechanism, achieved through structured routing and integration patterns rather than ad hoc, improvisational logic. This deterministic approach enhances the system’s stability and debuggability, moving RAG from a nebulous AI capability to a well-defined integration step.
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/92figure-4-1776763977934.jpg)
Achieving Multimodality Without Over-Reliance on Multimodal Models
A significant insight from this project is the ability to construct powerful multimodal systems without necessarily relying on monolithic, end-to-end multimodal models. Instead of directly feeding images to an LLM, screenshots are routed to TensorFlow Serving. There, a specialized ResNet50 model processes the images, generating labels and associated confidence scores. These results are then transformed into structured signals that the agent can incorporate into its reasoning process, leveraging concrete image insights rather than raw visual data. This strategy offers several compelling advantages: it is more cost-effective, significantly more efficient, and easier to manage in production. Moreover, it ensures that LLMs remain focused on their core strengths—textual reasoning and generation—which is particularly crucial in high-stakes enterprise environments where predictability and cost control are paramount. This modular approach allows for optimized resource allocation and greater flexibility in model selection and updates.
Robustness by Design: Embracing Failure Explicitly
One of the most valuable lessons gleaned from this project was the profound importance of designing for failure, not just success. The real-world challenges encountered—such as subtle differences in TensorFlow Serving Docker images and model versions, large REST payloads (around 900KB for tensors) causing silent connection failures, cold-start latency on model servers, and undocumented HTTP limits in TensorFlow Serving—underscored the inherent unreliability of external dependencies. Rather than attempting to conceal these potential points of failure, the architecture is explicitly built to anticipate and gracefully handle them, thereby rendering the system more robust in the face of uncertainty.
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/5table-1-1776763977934.jpg)
To achieve this resilience, Apache Camel strategically wraps every external call with safeguards. These include Resilience4j circuit breakers to prevent cascading failures, meticulously defined timeouts, and sophisticated retry strategies. Furthermore, fallback options are implemented to protect key operations. For instance, even if image classification fails due to an upstream issue, the system is still engineered to provide a reliable triage decision based solely on text analysis and RAG. This intentional design choice exemplifies careful, resilient engineering, transforming potential system collapse into graceful degradation.
The Deliberate Choices: Justifying the Architecture
The architectural design of this system was the outcome of a series of deliberate choices, meticulously aimed at balancing functionality, reliability, and maintainability:
- Structured Outputs: Prioritizing machine-consumable, auditable JSON outputs over free-form conversational text.
- Explicit State Management: Avoiding implicit context or memory in the agent, relying instead on explicit inputs for each decision.
- Dedicated Tooling: Favoring specialized tools and models for specific tasks (e.g., image analysis, RAG) rather than overburdening a single, general-purpose LLM.
- Deterministic Workflows: Employing Camel’s routing capabilities to ensure predictable execution paths, even within probabilistic AI components.
- Enterprise Integration Patterns: Leveraging proven EIPs for resilience, monitoring, and control over AI interactions.
These constraints are not limitations but deliberate choices that keep the system understandable, operable, and maintainable by conventional engineering teams, rather than requiring an exclusive cadre of AI specialists. They represent a bridge between cutting-edge AI capabilities and established software engineering best practices.
/filters:no_upscale()/articles/orchestrating-agentic-multimodal-ai-pipelines-apache-camel/en/resources/68figure-5-1776763977934.jpg)
Broader Implications and Future Outlook
Agentic and multimodal AI are no longer aspirational concepts; they represent tangible architectural challenges confronting organizations today. The most significant takeaway from this approach transcends any single framework or model. It advocates for a fundamental shift in mindset: to treat AI components as inherently unreliable dependencies that necessitate rigorous management, to apply proven integration patterns to handle probabilistic systems, to maintain a clear separation between reasoning and execution, and to design explicitly for partial failures rather than anticipating flawless intelligence. The strategic combination of Apache Camel with modern AI tools like LangChain4j offers a practical and robust path forward. This approach honors decades of enterprise integration experience while harnessing the immense potential of emerging AI technologies. Ultimately, in production environments, robust architecture and disciplined engineering consistently prove more critical than raw model intelligence alone. This paradigm ensures that AI systems become not just intelligent, but also reliable, scalable, and governable assets within the modern enterprise landscape.





{kind=link}