Yelp Successfully Executes Zero-Downtime Upgrade of Over 1,000 Apache Cassandra Nodes, Setting a New Industry Standard

Yelp, the widely recognized platform for discovering local businesses, has achieved a significant engineering feat by successfully completing a large-scale upgrade of its Apache Cassandra infrastructure, encompassing more than 1,000 nodes, without incurring any service downtime. This remarkable accomplishment, meticulously detailed by Yelp’s Database Reliability Engineering (DBRE) team, offers a compelling blueprint for other organizations grappling with the complexities of managing and modernizing stateful systems at an extensive scale. The project underscores how a strategic combination of careful planning, phased execution, and robust automation can facilitate the seamless modernization of even the most critical and complex data infrastructures, ensuring continuous availability for millions of users reliant on Yelp’s services.
The Critical Role of Apache Cassandra at Yelp
Apache Cassandra, an open-source, distributed NoSQL database management system, is renowned for its high availability and linear scalability, making it a cornerstone technology for companies that manage massive amounts of data across multiple servers. For a platform like Yelp, which processes millions of reviews, business listings, and user interactions daily, Cassandra is not merely a database but a foundational component underpinning many of its core services. These services likely include real-time review processing, user activity feeds, personalized recommendations, search indexing, and the storage of vast quantities of unstructured and semi-structured data essential for Yelp’s operational functionality. Its ability to handle high write and read throughput with no single point of failure is crucial for maintaining the always-on nature expected by Yelp’s global user base.
The decision to embark on such a large-scale upgrade was driven by several factors inherent in the lifecycle of any major technology stack. Upgrading Cassandra versions typically brings substantial benefits, including enhanced performance optimizations, improved security features, access to new functionalities, and better resource utilization. For instance, newer versions often introduce more efficient compaction strategies, better garbage collection algorithms, and advanced query capabilities that can directly translate into a faster, more reliable user experience and reduced operational costs. However, upgrading a distributed database of this magnitude, particularly one that serves as the backbone for critical production workloads, presents a formidable challenge, primarily due to the inherent complexities of maintaining data consistency and availability across a vast, interconnected network of nodes.
The Dauntless Challenge: Upgrading 1,000+ Stateful Nodes Without Interruption
The sheer scale of Yelp’s Cassandra infrastructure – exceeding 1,000 nodes – amplifies the inherent difficulties associated with upgrading stateful systems. Unlike stateless services, such as simple web servers that can be easily replaced or scaled without concern for data persistence, distributed databases like Cassandra are intricately tied to their data. Each node holds a portion of the overall dataset, replicates it across the cluster for redundancy, and participates in maintaining data consistency through complex protocols like quorum reads and writes. This interdependence means that any modification or upgrade to an individual node must be carefully orchestrated to avoid disrupting the overall cluster’s integrity, availability, or the consistency of the data it serves.
For a company like Yelp, downtime is not just an inconvenience; it represents a direct impact on revenue, user trust, and brand reputation. Even a brief outage can lead to lost user engagement, frustrated business owners, and a ripple effect across interconnected services. In an era where digital services are expected to be continuously available, traditional maintenance windows, which involve scheduled periods of service unavailability, are increasingly becoming obsolete. Modern cloud-native engineering principles, embraced by leaders like Yelp, demand strategies that eliminate downtime as a constraint, making "always-on" the default operational paradigm. This elevates the challenge of upgrading critical infrastructure from a routine task to a high-stakes engineering endeavor requiring meticulous precision and innovative solutions. The effort to upgrade Cassandra without interruption highlights Yelp’s commitment to delivering an uninterrupted, high-quality experience to its users and business partners.
A Meticulous Blueprint: Yelp’s Zero-Downtime Strategy Unveiled
Yelp’s success in this monumental upgrade was not serendipitous but the result of a meticulously planned and executed strategy that leveraged best practices in distributed systems management, automation, and operational rigor. The core tenets of their approach revolved around a phased execution model, stringent compatibility adherence, and a heavy investment in automation and observability.
Phase 1: Meticulous Planning and Preparation
The foundation of the entire upgrade process was an extensive planning phase, spearheaded by Yelp’s expert Database Reliability Engineering team. This involved a comprehensive risk assessment, identifying potential failure points, and developing robust rollback plans for every conceivable scenario. Compatibility checks were paramount; ensuring that the new Cassandra version could seamlessly interact with the existing version during the rolling upgrade and that application code remained compatible throughout the transition. Extensive testing in staging environments, mimicking the production topology and workload, was crucial for validating the upgrade process and identifying any unforeseen issues before touching live systems. This phase also included resource allocation, ensuring that sufficient compute, storage, and network resources were available to handle the transition and potential temporary load shifts. A spokesperson from Yelp’s engineering department, speaking on the importance of this initial stage, might emphasize, "The success of any large-scale infrastructure project hinges on the depth and breadth of its planning. Our DBRE team left no stone unturned, simulating every possible scenario to build confidence and mitigate risks long before touching our production environment."
Phase 2: Phased Execution with a Rolling Upgrade Model
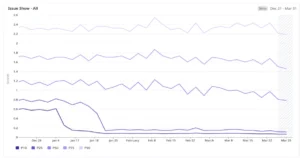
At the heart of Yelp’s zero-downtime strategy was the adoption of a rolling upgrade methodology. This technique involves incrementally upgrading nodes in a cluster, one or a small batch at a time, while the rest of the cluster remains operational and continues to serve traffic. For Cassandra, this means:
- Node Isolation: A small, predetermined batch of nodes is temporarily removed from active service (e.g., by stopping the Cassandra process or draining traffic).
- Upgrade and Configuration: These isolated nodes are then upgraded to the new Cassandra version, and any necessary configuration changes are applied.
- Validation and Reintegration: After the upgrade, the nodes are carefully validated to ensure they are healthy and correctly configured. They are then brought back into the cluster, where they begin to synchronize with the remaining older version nodes. Cassandra’s gossip protocol and replication mechanisms ensure that data consistency is maintained during this mixed-version state.
- Cluster Rebalancing and Repair: Following the reintegration of an upgraded batch, the cluster is given time to rebalance and perform necessary data repairs. This ensures that all data partitions are correctly distributed and replicated across the new topology, and any inconsistencies that might have arisen during the brief node downtime are resolved.
- Iteration: This process is repeated for subsequent batches of nodes until the entire 1,000+ node cluster is running the new Cassandra version.
This meticulous, iterative approach ensured that at no point was a significant portion of the cluster offline, thereby preserving overall availability and data consistency. The adherence to strict compatibility principles between the old and new Cassandra versions was critical, allowing the cluster to operate in a mixed-mode state for extended periods without encountering compatibility issues or data corruption.
Phase 3: The Backbone of Success – Automation and Observability
The scale of Yelp’s Cassandra infrastructure made manual intervention impractical and prone to human error. Therefore, automation was not merely a convenience but an absolute necessity. Yelp’s team invested heavily in developing sophisticated automated orchestration tools and custom scripts to manage the upgrade process. These tools were responsible for:
- Node Selection and Isolation: Automatically identifying nodes for the next upgrade batch and gracefully removing them from service.
- Software Deployment: Automating the installation of new Cassandra versions and configuration updates.
- Health Checks and Validation: Running automated diagnostics and health checks on upgraded nodes before reintegrating them.
- Rollback Procedures: Providing automated pathways to revert changes if any issues were detected, ensuring a safety net.
Coupled with automation, a robust observability stack provided real-time visibility into the health and performance of the Cassandra cluster throughout the upgrade. This included:
- Comprehensive Monitoring: Collecting thousands of metrics from each Cassandra node (e.g., CPU utilization, memory usage, disk I/O, network traffic, compaction progress, read/write latency, error rates, garbage collection statistics).
- Alerting Systems: Configuring intelligent alerts to proactively notify the DBRE team of any anomalies, performance degradation, or potential issues that could impact service quality.
- Centralized Logging: Aggregating logs from all nodes to facilitate rapid debugging and root cause analysis.
- Dynamic Dashboards: Providing engineers with intuitive, real-time dashboards to visualize the cluster’s state, track upgrade progress, and quickly identify any deviations from expected behavior.
"Our investment in automation and observability was non-negotiable," remarked a lead engineer on Yelp’s DBRE team. "It allowed us to execute with confidence, scaling our efforts across a thousand nodes while maintaining a granular view of every component. This enabled us to detect and address potential issues within minutes, long before they could impact our users."
Industry Context and Precedents: Beyond Traditional Migrations
Yelp’s successful in-place upgrade of such a large Cassandra cluster distinguishes itself from other common zero-downtime migration strategies. Industry-wide, organizations often rely on techniques such as:
- Dual Writes: Writing data simultaneously to both the old and new database systems, then gradually migrating reads to the new system. While effective, this adds significant application-level complexity and requires careful data synchronization.
- Replication to New Clusters (Blue-Green Deployment for Databases): Setting up an entirely new cluster alongside the existing one, replicating all data, and then performing a cutover by shifting traffic. This is a very safe method but can be resource-intensive, requiring double the infrastructure for a period.
- Logical Replication and Change Data Capture (CDC): Using tools to replicate data changes from the old system to a new one, often across different database technologies.
Yelp’s approach demonstrates that even an in-place upgrade of a large, stateful, distributed database can be achieved safely and efficiently with the right combination of engineering discipline, robust tooling, and a deep understanding of the underlying database’s architecture. This method, when executed flawlessly, can be more resource-efficient than setting up entirely new clusters, making it an attractive option for organizations with significant infrastructure investments.
This achievement also aligns with a broader trend in cloud-native engineering and DevOps culture, where continuous delivery and continuous operations are paramount. Companies are moving away from monolithic releases and disruptive maintenance windows towards incremental, seamless updates. Other organizations tackling similar challenges, such as migrating Cassandra clusters across different Kubernetes environments (e.g., Amazon EKS), have also highlighted the critical importance of careful planning, staged rollouts, and strong operational controls to achieve zero downtime in production systems. These examples collectively reinforce the evolving definition of reliability in modern software engineering: it’s no longer just about maintaining uptime, but about enabling continuous, non-disruptive change.
Broader Impact and Future Benchmarks
Yelp’s zero-downtime Cassandra upgrade represents more than just a technical triumph; it carries significant implications for both Yelp and the broader technology industry.
Implications for Yelp
For Yelp, this successful upgrade reinforces its reputation as a leader in operational excellence and advanced infrastructure management. It ensures that its critical data infrastructure is running on a modern, performant, and secure version of Cassandra, allowing the company to leverage the latest features and optimizations. This directly translates to:
- Enhanced Reliability and Performance: A more stable and efficient database translates to faster response times for users, fewer errors, and a more robust platform overall.
- Improved Security Posture: Newer software versions typically include patches for known vulnerabilities, reducing security risks.
- Competitive Advantage: The ability to perform such complex upgrades without disruption gives Yelp a significant edge, enabling faster innovation cycles and greater agility in adopting new technologies.
- Developer Productivity: A modern, well-maintained database environment simplifies development and reduces the burden on engineering teams.
Implications for the Industry
Yelp’s detailed account of their upgrade journey serves as a powerful case study and a benchmark for the entire industry. It demonstrates that:
- Zero-Downtime for Stateful Systems is Achievable at Scale: This dispels the myth that large-scale database upgrades inherently require service interruptions. It encourages other organizations, particularly those reliant on distributed databases like Cassandra, MongoDB, or Kafka, to invest in similar strategies and operational rigor.
- The Value of DBRE Teams: The success underscores the critical importance of dedicated Database Reliability Engineering teams, whose specialized expertise in database internals, distributed systems, and operational automation is indispensable for managing complex data platforms.
- Investment in Automation and Observability Pays Dividends: The project provides tangible evidence that significant investment in robust automation frameworks and comprehensive observability tools is not an overhead but a fundamental requirement for modern, highly available systems.
- Evolution of Reliability Engineering: It solidifies the paradigm shift in reliability engineering, where the focus has expanded from simply keeping systems running to enabling seamless, continuous evolution and modernization without user impact. The ability to change safely and frequently is now a key metric of system reliability.
While the complexities of managing and upgrading distributed systems will continue to evolve, Yelp’s achievement provides a clear roadmap. It highlights that with the right combination of strategic planning, disciplined execution, advanced tooling, and a culture of continuous improvement, even the most challenging infrastructure modernization projects can be completed without compromising service availability. This sets a new, inspiring benchmark for engineering teams worldwide, proving that the future of always-on services is not just aspirational but eminently achievable.







{kind=link}