
In a decisive move to bolster crew health and safety during long-duration orbital missions, NASA’s Office of the Chief Health and Medical Officer (OCHMO) convened a specialized working group in April 2026 to evaluate the evolving risks of Venous Thromboembolism (VTE) in microgravity environments. This summit, which brought together leading vascular surgeons, hematologists, and aerospace medicine specialists, was prompted by the emergence of new clinical data revealing significant alterations in blood flow patterns among astronauts stationed aboard the International Space Station (ISS). The group’s primary objective was to synthesize recent research findings into updated Clinical Practice Guidelines (CPGs) that provide a roadmap for the prevention, diagnosis, and management of blood clots in space.
The April 2026 review represents the culmination of several years of intensive study following the initial recognition of VTE as a potential occupational hazard for astronauts. By reviewing updated case information and a growing repository of vascular ultrasound data, the OCHMO working group has refined its understanding of how the absence of gravity influences hemodynamics, particularly within the venous system of the upper body. The resulting recommendations emphasize a proactive, evidence-based approach to mitigating a condition that could otherwise jeopardize mission success and crew longevity.
The Evolution of VTE Risk Management in Spaceflight
The formal investigation into spaceflight-associated VTE gained significant momentum in October 2024, when NASA first established a dedicated working group to address the diagnosis of venous clots in crew members. Prior to this, the medical community had largely focused on the risks of bone density loss and muscle atrophy. However, the discovery of a thrombus in the internal jugular vein (IJV) of an astronaut during an ISS mission—a discovery made during a routine vascular research study—shifted the agency’s focus toward the cardiovascular and hematological impacts of microgravity.
Between the initial 2024 assembly and the April 2026 meeting, NASA and its international partners expanded their monitoring protocols. Researchers utilized high-resolution ultrasound to track blood flow in the IJV and other major vessels. The data gathered during this period revealed a concerning phenomenon: "altered blood flow status." In the absence of gravity, the fluid shift toward the head (cephalad shift) causes the veins in the neck and upper chest to become chronically distended. This congestion, combined with instances of stagnant or even retrograde (backward) blood flow, creates a terrestrial-like environment for Virchow’s Triad—the three factors known to contribute to thrombosis: venous stasis, endothelial injury, and hypercoagulability.
Key Findings of the April 2026 Working Group
The 2026 working group focused on several key data points that have emerged from recent ISS increments. One of the most significant findings involved the frequency of stagnant flow in the left internal jugular vein compared to the right. Analysis showed that the anatomical differences in venous drainage paths from the head to the heart become more pronounced in microgravity, potentially making certain crew members more susceptible to clotting based on their unique vascular architecture.
Furthermore, the working group reviewed the efficacy of pharmacological countermeasures currently available on the ISS. The challenge of treating VTE in space is multifaceted, involving the logistics of administering anticoagulants, the risk of hemorrhage in a remote environment, and the physiological changes that may affect how the body metabolizes medication. The April 2026 session was instrumental in determining which "evidence-based clinical practice recommendations" should be prioritized to balance the risk of clotting against the risk of bleeding.
Updated Clinical Practice Recommendations
The summary of the working group’s recommendations highlights a shift from reactive treatment to proactive surveillance. While the full technical details are distributed through NASA’s internal medical channels, the primary pillars of the updated guidelines include:
- Enhanced Pre-flight Screening: Implementing more rigorous vascular imaging and genetic screening for prothrombotic factors during the astronaut selection and pre-launch phases to identify individuals at higher baseline risk.
- Standardized In-flight Ultrasound Monitoring: Establishing a mandatory schedule for vascular ultrasound examinations for all long-duration crew members. These exams are designed to detect early signs of stagnant flow or asymptomatic thrombi before they progress to life-threatening pulmonary embolisms.
- Refined Anticoagulation Protocols: Developing a tiered approach to anticoagulation, utilizing both injectable and oral medications. The guidelines now specify the precise dosages and durations for "prophylactic" versus "therapeutic" intervention, tailored specifically to the microgravity environment.
- Physical Countermeasures: Increasing the use of Lower Body Negative Pressure (LBNP) devices and specific exercise regimens designed to encourage venous return to the lower extremities, thereby reducing the pressure and congestion in the head and neck veins.
- Telemedical Integration: Streamlining the communication between on-orbit crew members and Earth-based vascular specialists to ensure that any suspicious ultrasound findings are reviewed in real-time by subject matter experts.
A Chronology of NASA’s Response to Vascular Risks
The path to the 2026 guidelines has been marked by several critical milestones in aerospace medicine. The timeline reflects an accelerating pace of discovery and policy implementation:
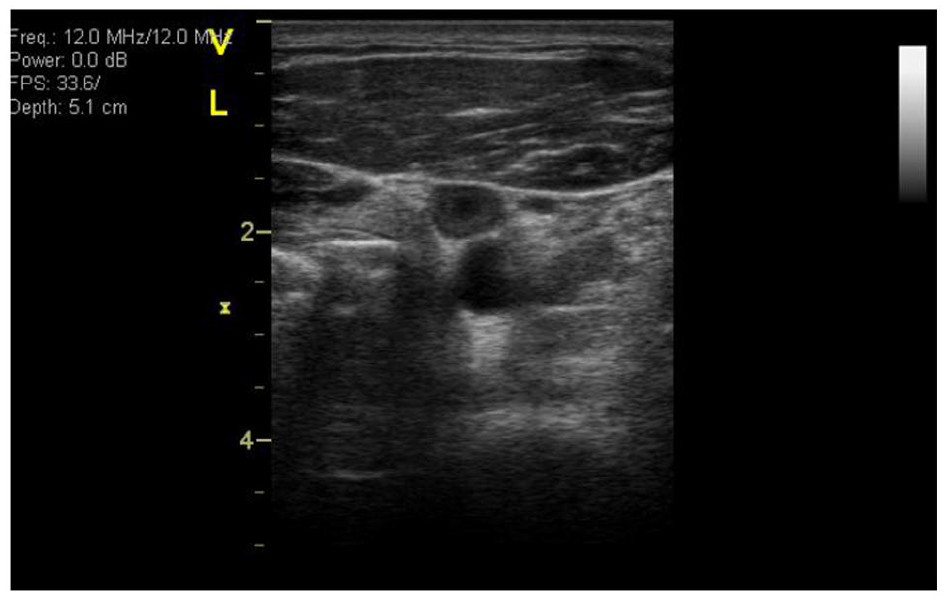
- 2019–2020: The first documented case of an IJV thrombus occurs on the ISS. This event serves as a "sentinel case," prompting NASA to incorporate vascular ultrasound into routine health checks rather than just research protocols.
- October 2024: NASA OCHMO forms the first official VTE working group. This body establishes the initial framework for managing clots in space and begins the process of updating the Clinical Practice Guidelines.
- 2025: A large-scale observational study is conducted across multiple ISS increments, involving both NASA astronauts and international partners. This study focuses on "venous stasis" and the physiological triggers of clotting in weightlessness.
- April 2026: The OCHMO working group reconvenes to finalize the updated recommendations. This meeting incorporates the latest data on altered blood flow and the success rates of various in-flight treatments.
Scientific Analysis of Implications
The implications of the 2026 OCHMO findings extend far beyond the current operations of the International Space Station. As NASA prepares for the Artemis missions, which will return humans to the lunar surface, and eventually for the first crewed mission to Mars, the management of VTE becomes a critical mission-safety factor.
On a mission to Mars, which could last up to three years, the luxury of a rapid evacuation to Earth in the event of a medical emergency is non-existent. A pulmonary embolism—a condition where a blood clot travels to the lungs—could be fatal without the intensive care facilities found in terrestrial hospitals. Therefore, the ability to prevent clots or manage them effectively using only the resources available on a spacecraft is paramount.
The "altered blood flow status" identified by the working group also raises questions about other potential health issues. Chronic venous congestion in the head is a suspected contributor to Spaceflight-Associated Neuro-ocular Syndrome (SANS), which affects the vision of many astronauts. By addressing the vascular health of the internal jugular veins, NASA may also be taking steps toward mitigating the risks of SANS, illustrating the interconnected nature of spaceflight physiology.
Official Responses and Collaborative Efforts
While the working group’s primary focus is internal, the findings have significant resonance with the broader scientific community. Statements from NASA’s Chief Health and Medical Officer emphasize that the agency is committed to transparency and the sharing of medical knowledge with international space agencies and the burgeoning commercial spaceflight sector.
"The safety of our crew is the highest priority for NASA," an OCHMO representative noted during the briefing. "The updates provided by the April 2026 working group ensure that we are using the most current data to protect those who venture into the extreme environment of space. These guidelines are not just for the ISS; they are the foundation for our journey to the Moon and Mars."
Commercial entities, such as SpaceX and Axiom Space, are also expected to adopt these clinical guidelines for their private astronaut missions. As more civilians enter low-Earth orbit, the medical data gathered by NASA provides a vital safety net for the entire space industry. The collaborative nature of the 2026 review ensures that the protocols are robust enough to handle the diverse physiological profiles of a wider range of space travelers.
Looking Toward the Future of Space Medicine
The work of the OCHMO working group is far from finished. As NASA continues to gather data from the ISS and future lunar outposts, the Clinical Practice Guidelines will remain a living document, subject to further refinement. Future research is expected to delve deeper into the molecular and cellular changes that occur in the blood during spaceflight, potentially leading to the development of new, space-specific anticoagulants with fewer side effects.
The April 2026 update serves as a reminder of the inherent risks of space exploration and the rigorous scientific effort required to overcome them. By transforming a newly discovered risk—venous thromboembolism—into a manageable medical condition through disciplined research and clinical excellence, NASA continues to pave the way for the next generation of explorers. The lessons learned in the pursuit of vascular health in orbit may also have applications on Earth, particularly in treating patients with restricted mobility or those suffering from terrestrial venous diseases, further cementing the dual-use value of NASA’s medical research.







{kind=link}